Azure Data Factory (ADF)
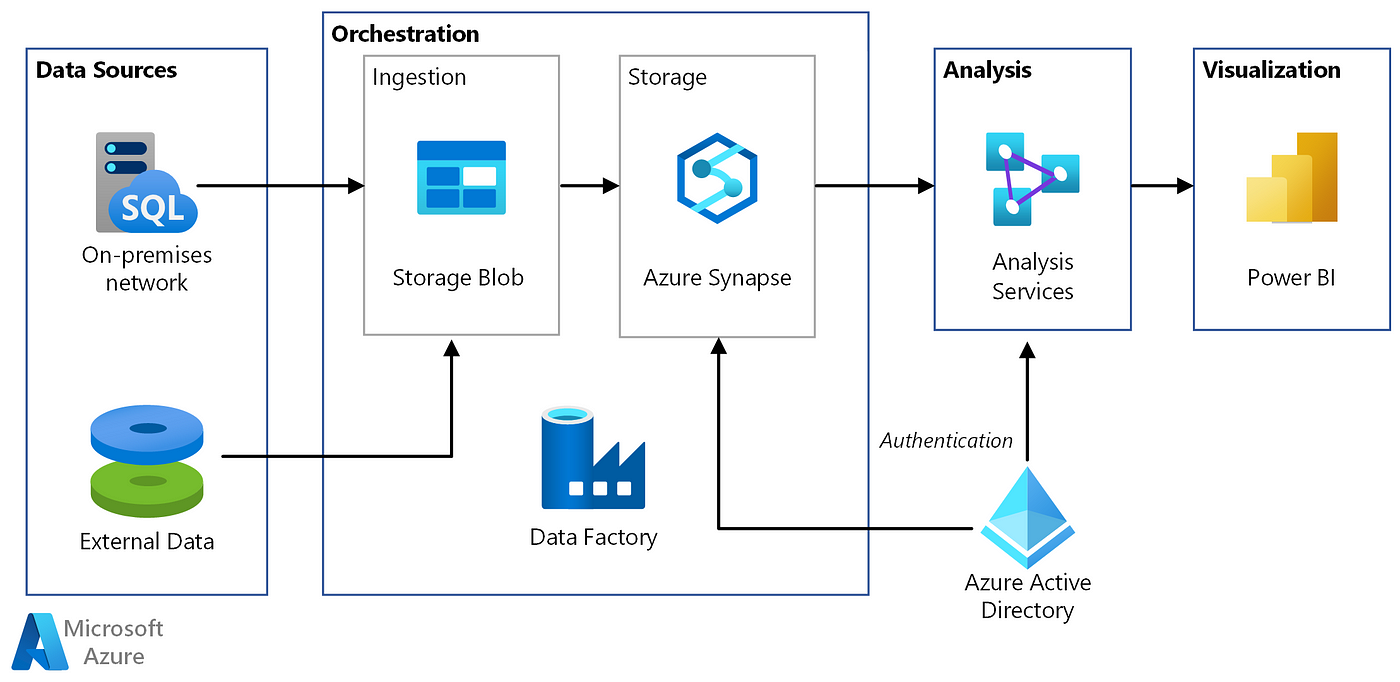
Azure Data Factory is Azure’s cloud ETL service for scale-out serverless data integration and data transformation. It offers a code-free UI for intuitive authoring and single-pane-of-glass monitoring and management. You can also lift and shift existing SSIS packages to Azure and run them with full compatibility in ADF. SSIS Integration Runtime offers a fully managed service, so you don’t have to worry about infrastructure management.
How does it work?
Data Factory contains a series of interconnected systems that provide a complete end-to-end platform for data engineers.

Main Components
An Azure subscription might have one or more Azure Data Factory instances (or data factories). Azure Data Factory is composed of below key components.
- Pipelines
- Activities
- Datasets
- Linked services
- Data Flows
- Integration Runtimes
These components work together to provide the platform on which you can compose data-driven workflows with steps to move and transform data.

Mapping data flows performance and tuning guide
Mapping data flows in Azure Data Factory and Synapse pipelines provide a code-free interface to design and run data transformations at scale. If you’re not familiar with mapping data flows, see the Mapping Data Flow Overview. This article highlights various ways to tune and optimize your data flows so that they meet your performance benchmarks.
Monitoring data flow performance
Once you verify your transformation logic using debug mode, run your data flow end-to-end as an activity in a pipeline. Data flows are operationalized in a pipeline using the execute data flow activity. The data flow activity has a unique monitoring experience compared to other activities that displays a detailed execution plan and performance profile of the transformation logic. To view detailed monitoring information of a data flow, click on the eyeglasses icon in the activity run output of a pipeline. For more information, see Monitoring mapping data flows.

When monitoring data flow performance, there are four possible bottlenecks to look out for:
- Cluster start-up time
- Reading from a source
- Transformation time
- Writing to a sink

Azure Data Factory limitations
Alongside Azure Data Factory’s benefits, it’s important to consider its limitations.
Custom data collectors
While you can create data pipelines based on a variety of common sources including mainstream databases and cloud storage services without writing code in Azure Data Factory, you’ll need to write custom code to configure nonstandard data sources. This may prove challenging if, for example, you rely on proprietary databases that can’t integrate with Azure Data Factory with the prebuilt connectors.
Focus on Azure
Azure Data Factory supports some data sources hosted outside of Azure, but it’s designed first and foremost for building integration pipelines that connect to Azure or other Microsoft resource types. This is a downside if you have a multi-cloud strategy that runs most of your workloads outside Azure. In that case, you may be better served by a third-party offering such as Apache Airflow that’s not tied to specific vendors or platforms.
Long-term expense
While consumption-based pricing is attractive in some ways, its long-term total cost of ownership may be higher than that of on-premises options. If you plan to run data integration services for years, you may save money by hosting it on your own infrastructure.

